资源简介
设计SAMPLE语言的词法分析器
检查要求:
启动程序后,先输出作者姓名、班级、学号(可用汉语、英语或拼音);
请求输入测试程序名,键入程序名后自动开始词法分析并输出结果;
输出结果为单词的二元式序列(样式见样板输出1和2);
要求能发现下列词法错误和指出错误性质和位置:
非法字符,即不是SAMPLE字符集的符号;
字符常数缺右边的单引号(字符常数要求左、右边用单引号界定,不能跨行);
注释部分缺右边的界符*/(注释要求左右边分别用/*和*/界定,不能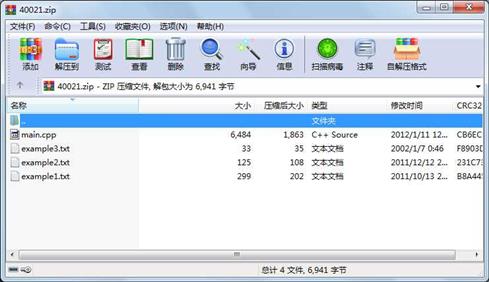
代码片段和文件信息
#include
#include
#include
#include
#include
#include
#include
using namespace std;
bool flag=true;
int count=1;//record the total number of identifier 3637 and 38
int col=0;//a sign of 5 outputs every line
char *identifier[62]={“““and““array““begin““bool““call““case““char““constant““dim““do““else““end““false““for““if“
“input““integer““not““of““or““output““procedure““program““read““real““repeat““set““stop““then““to“
“true““until““var““while““write““““““““(““)““*““*/““+““““-“
“.““..““/““/*““:““:=““;““<““<=““<>““=““>““>=““[““]“};
char word[1000][20];
stack S;
/** identify an identifier among 1 to 35*/
int match(char* token)
{
for(int i=1;i<=60;i++)
if(strcmp(tokenidentifier[i])==0)
return i;
return 0;
}
/**output the result one by one*/
void printToken(int ichar* token)
{
if(col%5==0)
{
col=0;
cout<
col++;
if(i>35 && i<39)
{
//note the work in an array
int j=0;
for(j=0;j
if(strcmp(tokenword[j])==0)
{
cout<<“(“<
}
}
strcpy(word[count]token);
cout<<“(“<
else
cout<<“(“<
return;
}
void scanner()
{
//open the file
char fileName[50];
cout<<“请输入需要检测文件的路径:“<
fstream iof;
iof.open(fileNameios::in);
if(!iof)
{
cout<<“Can‘t find the file.“<
}
/*identify*/
int nullLine=0;
int line=0;
//Read a line every time
const int LINE_LEN = 100;
char getRead[102];
loop1: iof.getline(getReadLINE_LEN);
line++;
if(!flag)
{
cout<<“\n“<<“Line“<
}
if (getRead[0]==‘\0‘)
{
nullLine++;
if(nullLine==3){
cout<
}
goto loop1;
}
nullLine=0;
char token[20];
char ch;
int i=0j;
while(i
if(getRead[i]==‘\0‘ || getRead[i]==‘?‘)
goto loop1;
ch=getRead[i++];
if(isalpha(ch)){//between a and z or between A and Z
j=1;
token[0]=ch;
ch=getRead[i++];
while(isalnum(ch))
{
token[j++]=ch;
ch=getRead[i++];
}
token[j]=‘\0‘;
i--;
int m=match(token);
if (m)
{
printToken(mtoken);
}
else printToken(36token);
}
else if(isalnum(ch) && i
char token[20];
int k=0;
token[k++]=ch;
while(isalnum(ch) && i
ch=getRead[i++];
token[k++]=ch;
if(isalpha(ch))
{
cout<<“\n“<<“Line“<
}
}
token[k]=‘\0‘;
i--;
属性 大小 日期 时间 名称
----------- --------- ---------- ----- ----
文件 299 2011-10-13 20:11 example1.txt
文件 125 2011-12-12 21:33 example2.txt
文件 33 2002-01-07 00:46 example3.txt
文件 6484 2012-01-11 12:17 main.cpp
相关资源
- 微软masm汇编编译器
- 编译原理实验工具及参考源码(lex&
- 类pascal语言编译器(编译原理实验)
- 编译原理课程设计:词法语法编译器
- 中科院 编译原理 习题及解答
- 编译原理四元式和逆波兰式
- unity3d反编译工具
- 汇编语言编译器masm5.0
- 《编译原理》清华大学版中的pl0扩充
- PL/0功能扩充break功能
- 编译词法分析器识别关键字常数和符
- SAMPLE (类pascal) 词法分析程序 C 版
- uCOS编译环境建立 BC45 TASM
- Delphi做的用于分析Pascal语言的词法分
- zlib 最新 1.2.8 win32 win64 编译好的dll
- 编译原理LR(0)语法分析
- 编译原理中间代码生成程序
- 编译原理:LR分析程序
- C编译器源代码(超级牛b).rar
- Delphi反编译工具的源码
- 小程序反编译文件wxappUnpacker.rar
- win10 64位下编译的opencv4.5.5库,opencv
- 易语言模块反编译助手
- librdkafka win7 64位 vs2015编译Release版本
- 编译原理实验:词法分析,语法分析
- 吉林大学编译原理课件
- delphi 反编译工具 源码
- 音频测试文件pcmmp3aacamrg711ag711u等多种
- 编译好的json_lib.lib 包含64位,32位,头
- frcc.exe fastreport编译中文没乱码
 川公网安备 51152502000135号
川公网安备 51152502000135号
评论
共有 条评论