资源简介
python爬虫相关:
由于很多网站上的视频只提供在线观看,没有下载入口,故有必要进行网络爬虫获取视频资源。
利用requests获取网页源代码中的m3u8链接,对链接进行逐步解析,获取ts列表,下载所有ts文件,将其合并生成mp4文件。做到对视频的爬取。
同名博文相关代码。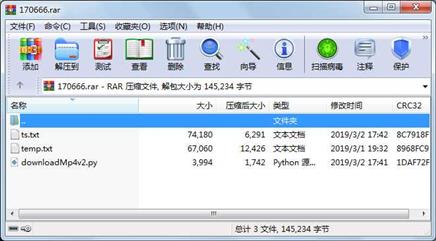
代码片段和文件信息
import requests
import os
# 字符(十六进制)转ASCII码
def hexToAscii(h):
d = int(h16) # 转成十进制
return chr(d) # 转成ASCII码
# 从得到的html代码中获取m3u8链接(不同网站有区别)
def getM3u8(http_s):
ret1 = http_s.find(“unescape“)
ret2 = http_s.find(“.m3u8“)
ret3 = http_s.find(“http“ ret1 ret2) # “unescape“和“.m3u8“之间找“http“
m3u8_url_1 = http_s[ret3: ret2 + 5] # 未解码的m3u8链接
# 下面对链接进行解码
while True:
idx = m3u8_url_1.find(‘%‘)
if idx != -1:
m3u8_url_1 = m3u8_url_1.replace(m3u8_url_1[idx:idx+3] hexToAscii(m3u8_url_1[idx+1:idx+3]))
else:
break
return m3u8_url_1
# 寻找字符串s中最后出现字符c的index
def findLastchr(s c):
ls = []
sum = 0
while True:
i = s.find(c)
if i != -1:
s = s[i+1:]
ls.append(i)
else:
break
for i in range(len(ls)):
sum += (ls[i] + 1)
return sum - 1
def getM3u8_2(m3u8_url_1):
r1 = requests.get(m3u8_url_1)
r1.raise_for_status()
text = r1.text
idx = findLastchr(text ‘\n‘)
key = text[idx + 1:] # 得到第一层m3u8中的key
idx = findLastchr(m3u8_url_1 ‘/‘)
m3u8_url_2 = m3u8_url_1[:idx + 1] + key # 组成第二层的m3u8链接
return m3u8_url_2
# 从最原始的url-->生成一个ts列表的文件
def getTsFile(url filename):
try:
r = requests.get(url)
r.encoding = r.apparent_encoding
r.raise_for_status()
http_s = r.text
m3u8_url_1 = getM3u8(http_s)
print(“第一层m3u8链接“ + m3u8_url_1)
m3u8_url_2 = getM3u8_2(m3u8_url_1)
print(“第二层m3u8链接“ + m3u8_url_2)
# 通过新的m3u8链接,获取真正的ts播放列表
# 由于列表比较长,为他创建一个txt文件
r2 = requests.get(m3u8_url_2)
f = open(filename “w“ encoding=“utf-8“) # 这里要改成utf-8编码,不然默认gbk
f.write(r2.text)
f.close()
print(“创建ts列表文件成功“)
return “success“
except:
print(“爬取失败“)
return “failed“
# 提取ts列表文件的内容,逐个拼接ts的url,形成list
def getPlayList(filename m3u8_url_2):
ls = []
f = open(filename “r“)
line = “ “ # line不能为空,不然进不去下面的循环
idx = findLastchr(m3u8_url_2 ‘/‘)
while line:
line = f.readline()
if line != ‘‘ and line[0] != ‘#‘:
line = m3u8_url_2[:idx+1] + line
ls.append(line[:-1]) # 去掉‘\n‘
return ls
# 批量下载ts文件
def loadTs(ls):
root = “D://mp4//“
length = len(ls)
try:
if not os.path.exists(root):
os.mkdir(root)
for i in range(length):
path = root + ls[i][-7:]
r = requests.get(ls[i])
with open(path ‘wb‘) as f:
f.write(r.content)
f.close()
print(path + “ --> OK ( {} / {} ){:.2f}%“.format(i length i*100/length))
print(“全部ts下载完毕“)
except:
print(“批量下载失败“)
# 整合所有ts文件,保存为mp4格式
def tsToMp4():
print(“开始合并...“)
root = “D://mp4//“
outdir = “output“
os.chdir(root)属性 大小 日期 时间 名称
----------- --------- ---------- ----- ----
文件 3994 2019-03-02 17:41 downloadMp4v2.py
文件 67060 2019-03-01 19:32 temp.txt
文件 74180 2019-03-02 17:42 ts.txt
----------- --------- ---------- ----- ----
145234 3
相关资源
- 二级考试python试题12套(包括选择题和
- pywin32_python3.6_64位
- python+ selenium教程
- PycURL(Windows7/Win32)Python2.7安装包 P
- 英文原版-Scientific Computing with Python
- 7.图像风格迁移 基于深度学习 pyt
- 基于Python的学生管理系统
- A Byte of Python(简明Python教程)(第
- Python实例174946
- Python 人脸识别
- Python 人事管理系统
- 一个多线程智能爬虫,爬取网站小说
- 基于python-flask的个人博客系统
- 计算机视觉应用开发流程
- python 调用sftp断点续传文件
- python socket游戏
- 基于Python爬虫爬取天气预报信息
- python函数编程和讲解
- 顶点小说单本书爬虫.py
- Python开发的个人博客
- 基于python的三层神经网络模型搭建
- python实现自动操作windows应用
- python人脸识别(opencv)
- python 绘图(方形、线条、圆形)
- python疫情卡UN管控
- python 连连看小游戏源码
- 基于PyQt5的视频播放器设计
- 一个简单的python爬虫
- csv文件行列转换python实现代码
- Python操作Mysql教程手册
 川公网安备 51152502000135号
川公网安备 51152502000135号
评论
共有 条评论