资源简介
实验报告见我的博客。
本压缩包内含python代码,建模的数据,预测的数据,字段解释。
本次设计要求实现信贷用户逾期预测功能。具体要求如下:利用所学数据挖掘算法对给定数据进行训练得出信用评估模型,依据模型对1000个贷款申请人是否逾期做出预测(0-未逾期 1-逾期)。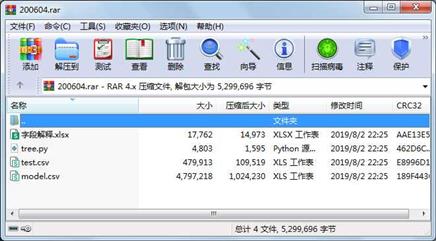
代码片段和文件信息
#!/usr/bin/env python
# coding: utf-8
from sklearn import tree
from sklearn.datasets import load_wine
import pandas as pda
#数据读取及预处理
fname=“E:\model.csv“
dataf=pda.read_csv(fnameencoding=“gbk“)
#数据预处理,缺失的空值填上平均值
dataf.iloc[:2:201]=dataf.iloc[:2:201].fillna(dataf.iloc[:2:201].median())
dataf.dropna(axis=0inplace=True)
x=dataf.iloc[:2:201].as_matrix()
y=dataf.iloc[:0].as_matrix()
xf=pda.Dataframe(x)
yf=pda.Dataframe(y)
from sklearn.model_selection import train_test_split
XtrainXtestYtrainYtest = train_test_split(xfyftest_size=0.1)
#剪枝,调值
‘‘‘
import matplotlib.pyplot as plt
test=[]
Max=0
I=J=K=0
for i in range(130):
for j in range(230):
for k in range(230):
clf=tree.DecisionTreeClassifier(
min_samples_leaf=i
min_samples_split=j
max_leaf_nodes=k
criterion=“entropy“
random_state=30
splitter=“random“
)
clf=clf.fit(XtrainYtrain)
score=clf.score(XtestYtest)
if score>Max:
Max=score
I=i
J=j
K=k
#test.append(score)
#plt.plot(range(130)testcolor=“red“label=“max_depth“)
#plt.legend()
#plt.show()
‘‘‘
#剪枝后的树,输出模型精确度
clf=tree.DecisionTreeClassifier(criterion=“entropy“
min_samples_leaf=1
min_samples_split=2
max_leaf_nodes=27
random_state=30
#max_depth=6
splitter=“random“
)
clf=clf.fit(XtrainYtrain)
score=clf.score(XtestYtest)
#score=clf.score(XtrainYtrain)
score
#决策树可视化
import graphviz
import pydotplus
feature_name=[‘x_001‘‘x_002‘‘x_003‘‘x_004‘‘x_005‘‘x_006‘‘x_007‘‘x_008‘‘x_009‘‘x_010‘
‘x_011‘‘x_012‘‘x_013‘‘x_014‘‘x_015‘‘x_016‘‘x_017‘‘x_018‘‘x_019‘‘x_020‘
‘x_021‘‘x_022‘‘x_023‘‘x_024‘‘x_025‘‘x_026‘‘x_027‘‘x_028‘‘x_029‘‘x_030‘
‘x_031‘‘x_032‘‘x_033‘‘x_034‘‘x_035‘‘x_036‘‘x_037‘‘x_038‘‘x_039‘‘x_040‘
‘x_041‘‘x_042‘‘x_043‘‘x_044‘‘x_045‘‘x_046‘‘x_047‘‘x_048‘‘x_049‘‘x_050‘
‘x_051‘‘x_052‘‘x_053‘‘x_054‘‘x_055‘‘x_056‘‘x_057‘‘x_058‘‘x_059‘‘x_060‘
‘x_061‘‘x_062‘‘x_063‘‘x_064‘‘x_065‘‘x_066‘‘x_067‘‘x_068‘‘x_069‘‘x_070‘
‘x_071‘‘x_072‘‘x_073‘‘x_074‘‘x_075‘‘x_076‘‘x_077‘‘x_078‘‘x_079‘‘x_080‘
‘x_081‘‘x_082‘‘x_083‘‘x_084‘‘x_085‘‘x_086‘‘x_087‘‘x_088‘‘x_089‘‘x_090‘
‘x_091‘‘x_092‘‘x_093‘‘x_094‘‘x_095‘‘x_096‘‘x_097‘‘x_098‘‘x_099‘‘x_100‘
‘x_101‘‘x_102‘‘x_103‘‘x_104‘‘x_105‘‘x_106‘‘x_107‘‘x_108‘‘x_109‘‘x_110‘
‘x_111‘‘x_112‘‘x_113‘‘x_114‘‘x_115‘‘x_116‘‘x_117‘‘x_118‘‘x_119‘‘x_120‘
‘x_121‘‘x_122‘‘x_123‘‘x_124‘‘x_125‘‘x_126‘ 属性 大小 日期 时间 名称
----------- --------- ---------- ----- ----
文件 4803 2019-08-02 22:25 tree.py
文件 17762 2019-08-02 22:25 字段解释.xlsx
文件 4797218 2019-08-02 22:25 model.csv
文件 479913 2019-08-02 22:25 test.csv
----------- --------- ---------- ----- ----
5299696 4
相关资源
- pycaret数据挖掘实践
- Python 数据挖掘入门与实践--代码与文
- 西电数据挖掘作业——医院数据处理
- Python数据挖掘入门与实践----Code完整代
- Python数据挖掘入门与实践 数据集及代
- adult数据集分析
- 西电数据挖掘作业之利用Python编程实
- Python数据挖掘和实战课程源码
- 数据挖掘课程设计.rar
- 《常用数据挖掘算法总结及Python实现
- pandas-0.25.3-cp37-cp37m-win_amd64.whl
- Python数据挖掘入门与实践-中文高清晰
- python数据挖掘入门与实践 pdf 高清完整
- 《Learning data mining with python》中文版
- Python数据挖掘入门与实践(中文完整
- 西电数据挖掘作业——VSM人脸识别算
- 常用数据挖掘算法总结及Python实现 文
- 常用数据挖掘算法总结及Python实现(
- 数据挖掘中的距离度量和相似度度量
- Web Scraping with Python_Collecting Data from
- python数据挖掘实验
- Djangopython实现数据挖掘和分析.doc
- python 数据挖掘入门与实战 pdf+代码
- 微博情感分析_python代码
- python数据挖掘入门与实践.zip
- Python数据挖掘实战.zip
- python数据挖掘概念、方法与实践.pdf
- python关于社交网站的数据挖掘和分析
- 源码python数据挖掘入门与实践源码
- python数据挖掘.zip
 川公网安备 51152502000135号
川公网安备 51152502000135号
评论
共有 条评论